Everything is Logistic Regression (And Some Extra)
Everything is Logistic Regression & Some Extra
From one equation to the architecture behind ChatGPT — without skipping the fundamentals
When I first encountered the LSTM diagram — the one with the forget gate, the input gate, the candidate gate, the output gate, the cell state threading through like a conveyor belt — I felt something I can only describe as pre-emptive defeat. Not confusion. Defeat. The kind you feel before you have even started.
I remember thinking: why does learning feel like being handed a circuit board and told to intuit electricity?
the diagram that made me want to close the tab
Over time, I noticed the reason it felt so hard — and it is not the complexity. It is a structural problem in how the field communicates.
Science moves forward by showing what is new. That is the incentive. To publish, to get cited, to be taken seriously, you need to demonstrate novelty. And so every paper presents its contribution as a clean break — a departure, not a continuation. The connections to prior work are mentioned briefly in a related work section, and then deliberately downplayed. Because if you connect too strongly to something that already exists, a reviewer will say: this is not sufficiently different from X. This has been done before.
I respect this deeply — every paper, every small increment, is genuinely moving science forward. But the side effect for learners is severe. When you try to understand attention, nobody tells you it is just a small network that sits between the encoder and decoder and asks "which encoder state matters right now?" Instead, it arrives in the literature as attention — a new word, a new diagram, a new framework — severed from the RNN it grew out of.

what a reviewer says if you connect your work too clearly to what came before
The result is a field that looks, from the outside, like an endless forest of unrelated trees. Each model has its own diagram, its own terminology, its own paper. The shared roots are underground, invisible. Nobody drew the map.
The field is like a Mandelbrot set. Each zoom reveals more complexity. Each paper adds a new layer. Progress is real and extraordinary — but nobody is required to make the whole thing learnable. The stack grows taller. The entry point gets higher. Eventually the foundations disappear into the cloud, and newcomers are handed a ladder that starts thirty floors up.
Someone has to look back. Someone has to dig through the long horizon of architectures and ask: what was the common building block all along? What is the root every branch grew from?
When I really tried to understand — not just memorize diagrams, but actually understand — I found it. The common skeleton is logistic regression. Put any model in an X-ray machine and you will find it everywhere: in every gate, every attention score, every feedforward layer. Each architecture is just logistic regression applied in a more complex configuration, used in a more clever way, stacked a little deeper. The variation is real — but the foundation is always the same.

me, after understanding what logistic regression actually is
This post builds from the ground up. We start from one equation — the simplest possible decision maker — and add one clever trick at a time. Each chapter is the previous chapter plus a single insight. By the end, the architecture behind GPT-4 will not look like magic. It will look like the logical next step.
Every model in this post — RNN, LSTM, GRU, Seq2Seq, Attention, Transformer — is built from two moves: a logistic regression that learns importance, and a weighted average that combines information. That is all.
The One Equation That Runs The World
Logistic Regression — the simplest decision maker
Before transformers, before attention, before RNNs — there is one equation. You have probably seen it. You may have dismissed it as too simple. That would be a mistake.
Logistic regression takes a bunch of input numbers, multiplies them by learned weights, adds a bias, and squashes the result through a sigmoid function to get a number between 0 and 1.
y = sigmoid(W·x + b) where: x = input vector (your data) W = weight matrix (what the model learns) b = bias (learned offset) sigmoid = 1 / (1 + e^-z) (squashes to 0..1) y = output (a decision)
The sigmoid function does something beautiful — it turns any real number into a probability. Feed it a very large number: you get close to 1. Feed it a very negative number: you get close to 0. It is a smooth, differentiable on/off switch.
Training is equally simple. You make a prediction, compare it to the correct answer with a loss function, then use backpropagation to figure out which weights caused the mistake and adjust them a little. Repeat thousands of times.
1. Make a prediction y = sigmoid(Wx + b) 2. Measure the mistake Loss = -log(y) if correct=1 3. Find who caused it dLoss/dW (backprop) 4. Fix weights a little W = W - lr × dLoss/dW 5. Repeat until good
That is it. That is the whole foundation. Everything that follows — every gate in an LSTM, every attention head in a transformer — is this same operation, applied cleverly in different contexts.
"Just logistic regression.
No extra tricks yet."
Stack It Deep
Deep Learning — logistic regression, layer by layer
One logistic regression makes one decision. It takes inputs, multiplies by weights, squashes through sigmoid. Done. But one decision is rarely enough. Real problems have layers of abstraction — raw pixels become edges, edges become shapes, shapes become faces. How do you build that?
You stack logistic regressions on top of each other. The output of one becomes the input of the next. That is deep learning. Nothing more.
Single logistic regression: y = sigmoid(W · x + b) input → one decision ───────────────────────────────────────────────── Two layers stacked: h = sigmoid(W1 · x + b1) ← layer 1 output y = sigmoid(W2 · h + b2) ← layer 2 takes layer 1 output ───────────────────────────────────────────────── Three layers — a "deep" network: h1 = sigmoid(W1 · x + b1) ← raw features h2 = sigmoid(W2 · h1 + b2) ← combinations of features y = sigmoid(W3 · h2 + b3) ← final decision Each layer is just: sigmoid(W · previous_output + b) Same equation. New inputs. That is all.
This is the entire secret of deep learning. Each layer transforms its input into a new representation — a new way of looking at the data. Early layers learn simple features. Later layers combine those features into increasingly abstract concepts. The model figures all of this out automatically through backpropagation.
"Deep learning is not a new idea. It is logistic regression, applied to itself, repeatedly."
But wait — there is a problem. If every layer is just a linear transformation followed by sigmoid, what stops the whole stack from collapsing into one single layer? Mathematically, two linear transformations composed together are still just one linear transformation.
The sigmoid is what saves us. It introduces nonlinearity — a bend in the function. After each linear step, sigmoid bends the output. The next layer then works with bent data. Stack enough bends and you can approximate any function in the universe. This is the Universal Approximation Theorem.
WITHOUT nonlinearity: h = W2 · (W1 · x + b1) + b2 = (W2·W1) · x + (W2·b1 + b2) = W_combined · x + b_combined Two layers = one layer. Stacking does nothing! ───────────────────────────────────────────────── WITH nonlinearity (sigmoid or ReLU): h = sigmoid(W1 · x + b1) y = sigmoid(W2 · h + b2) Now you CANNOT collapse this into one layer. The bend introduced by sigmoid breaks the linearity. Each layer genuinely adds new representational power. ───────────────────────────────────────────────── In practice, ReLU is used more than sigmoid in hidden layers: ReLU(z) = max(0, z) ← same idea, faster to compute sigmoid still used at output for probabilities
Training a deep network works the same way as training a single logistic regression — just with more bookkeeping. You make a prediction with a forward pass through all layers, compute the loss, then backpropagate the error signal backwards through every layer, adjusting every weight matrix along the way.
The chain rule of calculus handles the bookkeeping automatically. Each layer's gradient is computed from the layer above it. Frameworks like PyTorch do all of this for you.
Forward pass: x → Layer1 → h1 → Layer2 → h2 → Layer3 → y → Loss Backward pass (chain rule): dLoss/dW3 = dLoss/dy · dy/dW3 ← easy, close to loss dLoss/dW2 = dLoss/dy · dy/dh2 · dh2/dW2 ← one step further dLoss/dW1 = dLoss/dy · dy/dh2 · dh2/dh1 · dh1/dW1 ← deepest Each weight matrix gets its own gradient. Each gradient tells us: how much did this layer's weights contribute to the final mistake? Update each weight: W = W - learning_rate × dLoss/dW
Nobody tells the layers what to learn. Layer 1 might learn to detect individual word sentiment. Layer 2 might learn to detect negation ("not good"). Layer 3 might learn to combine everything into a final judgment. The structure emerges from training alone. You set up the architecture. Backprop figures out what each layer should do.
This is why the field is called deep learning — depth refers to the number of layers. A shallow network has one or two. A deep network has many. GPT-3 has 96 layers. Each one is the same pattern: linear transformation, nonlinearity, pass to next layer.
The naming changes. The architectures look different. But underneath every layer of every deep learning model, you will always find the same thing: a weight matrix, a bias, an activation function. Logistic regression in a new coat.
"Still just logistic regression.
Extra trick: apply it to itself, layer by layer."
Add Memory
The Recurrent Neural Network — logistic regression that remembers
Logistic regression has no memory. Feed it the word "bank" and it makes a decision. Feed it "river bank" versus "bank account" and it sees the same word each time — it has no idea what came before.
Language is sequential. Context matters. The fix is elegant: feed the output back in as input.
Regular logistic regression: y = tanh(W_x · x + b) RNN — add previous hidden state: h_t = tanh(W_x · x_t + W_h · h_{t-1} + b) ↑ memory of what came before!
The RNN processes one word at a time. At each step, it takes the current word embedding and the previous hidden state — the memory — and produces a new hidden state. That hidden state carries information about everything seen so far.
"The hidden state is a fingerprint of meaning. Not the word itself — a compressed summary of everything seen so far."
The RNN solves the memory problem but introduces a new one: vanishing gradients. When you backpropagate through many time steps, the gradient gets multiplied by small numbers over and over. By the time the signal reaches early time steps, it has nearly disappeared. Early words cannot learn properly.
Think of it like a game of telephone — information degrades over distance.
Backprop through time multiplies gradients: dL/dW_early = dL/dh_n × dh_n/dh_{n-1} × ... × dh_2/dh_1 Each term is a sigmoid derivative: between 0 and 0.25 0.2 × 0.2 × 0.2 × 0.2 × 0.2 = 0.00032 ← nearly zero! Early words get almost NO learning signal. Long-distance dependencies are hard to learn.
"Still just logistic regression.
Extra trick: feed the output back as input."
Fix The Memory
LSTM & GRU — four logistic regressions with different jobs
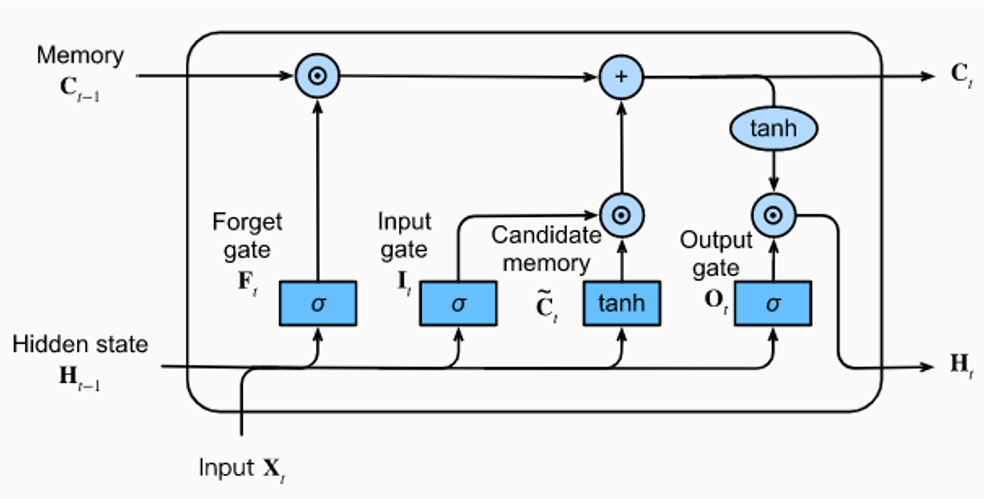
The RNN leaks memory. Information from early words fades before it can influence late decisions. The solution is not to make one big memory — it is to build a managed memory with explicit controls for what to keep, what to add, and what to output.
This is the LSTM. Forget the intimidating diagrams with arrows going everywhere. It is just four logistic regressions, each with a specific job.
Input at each step: x_t = current word h_{t-1} = short-term memory C_{t-1} = long-term memory ← new! the "conveyor belt" ───────────────────────────────────────────────── LR 1 — Forget Gate "what % of old memory to erase?" f = sigmoid(W_f · [h_{t-1}, x_t] + b_f) output: 0 = forget everything, 1 = keep everything LR 2 — Input Gate "how much new info to write?" i = sigmoid(W_i · [h_{t-1}, x_t] + b_i) LR 3 — Candidate "what is the new info?" g = tanh(W_g · [h_{t-1}, x_t] + b_g) LR 4 — Output Gate "what to output right now?" o = sigmoid(W_o · [h_{t-1}, x_t] + b_o) ───────────────────────────────────────────────── Then just arithmetic — NOT logistic regression: C_t = f × C_{t-1} + i × g ← update long-term memory h_t = o × tanh(C_t) ← update short-term memory
The long-term memory update uses addition, not multiplication. Gradients flow through addition with no shrinkage — the vanishing gradient problem is solved. The highway for information is now paved.
Notice what the LSTM is doing at its core: it is computing weighted averages. The forget gate produces a weight for old memory. The input gate produces a weight for new information. Then it takes a weighted average of the two. The weights are themselves produced by logistic regressions.
This is the pattern that will repeat through every architecture we study: logistic regression learns the weights, weighted average combines the information.
GRU — The Simpler Version
GRU asks: do we really need two separate memories and four gates? It merges them into two gates and one memory. Faster to train, slightly less expressive.
GRU Gates
r = sigmoid(W_r·[h,x])
z = sigmoid(W_z·[h,x])
h_t = (1-z)·h_{t-1} + z·g
"Still just logistic regression.
Extra trick: four LRs managing two memories."
Two Networks Talking
Seq2Seq — variable-length input, variable-length output
A single RNN can process a sequence. But translating "Hi" into "Bonjour mon ami" requires something different — the input and output have different lengths, and one must be fully understood before the other begins.
The solution: two RNNs. One reads. One writes.
The encoder throws away all its outputs and keeps only the final hidden state. That one vector — called the context vector — must carry the meaning of the entire input sentence into the decoder.
This works. For short sentences, it works well. For long sentences, it starts to fail. Squeezing "The quick brown fox jumped over the lazy dog and then sat down by the river" into a single fixed-size vector means something will be lost.
"The context vector is a bottleneck. One vector, responsible for carrying everything. This is the problem that attention was born to solve."
"Still just logistic regression.
Extra trick: two RNNs with an intermediate vector."
Learn What Matters
Attention — a third logistic regression that learns importance
Bahdanau et al. asked a simple question in 2014: why are we passing only the last hidden state to the decoder? We have all the encoder hidden states — h1, h2, h3 — sitting right there. Why not use all of them?
The answer is attention. At each decoder step, instead of using a fixed context vector, the decoder dynamically computes a fresh one by looking at all encoder states and deciding which ones are most relevant right now.
Setup: Encoder states: h1_e, h2_e, h3_e ("I", "love", "cats") Decoder query: h0_d (what decoder needs now) ───────────────────────────────────────────────── STEP 1 — Score each encoder state (small LR network) e1 = v^T · tanh(W1·h0_d + W2·h1_e) = 0.31 e2 = v^T · tanh(W1·h0_d + W2·h2_e) = 0.85 ← "love" is relevant! e3 = v^T · tanh(W1·h0_d + W2·h3_e) = 0.24 W1 brings decoder into shared space W2 brings encoder into shared space v collapses to a single relevance score ───────────────────────────────────────────────── STEP 2 — Softmax → attention weights softmax([0.31, 0.85, 0.24]) → α1=0.27, α2=0.47, α3=0.26 ← sum = 1.0 ───────────────────────────────────────────────── STEP 3 — Weighted average → context vector c1 = 0.27·h1_e + 0.47·h2_e + 0.26·h3_e ↑ "I" ↑ "love" ↑ "cats" dominated by "love" — exactly right for "J'aime"! ───────────────────────────────────────────────── STEP 4 — Decoder generates next word h1_d = RNN(h0_d, <START>, c1) → "J'aime" ✓ Repeat steps 1-4 for every decoder step. Each step gets its own fresh context vector!
The encoder and decoder hidden states come from different networks — they live in different spaces. You cannot just take their dot product. W1 and W2 are a learned bridge that projects both into a common space where comparison is meaningful. This bridge is trained by backpropagation alongside everything else.
Notice something beautiful here. The attention weights are just a weighted average — and the weights are learned by a small logistic regression. Same two moves as before. LR learns importance. Weighted average combines information. The only difference is that now we are computing this dynamically at every decoder step, over all encoder hidden states instead of just one.
Training pushes the network so that similar meanings produce similar hidden states. Nobody explicitly tells the model that "love" and "aime" are related. It figures this out from thousands of examples of English-French pairs. The similarity is entirely learned.
"Still just logistic regression.
Extra trick: a third LR that learns which input matters."
Every Word Talks To Every Word
The Transformer — throw away the RNN, keep the attention
Vaswani et al. asked an even more radical question in 2017: do we even need the RNN? Attention already lets every decoder step look at every encoder state. What if we extended that idea — what if every word in a sentence looked at every other word directly, with no recurrence at all?
This is self-attention. And it is the transformer.
For each word, create three vectors: q_i = W_Q · x_i "what am I looking for?" k_i = W_K · x_i "what do I contain?" v_i = W_V · x_i "what do I give?" Honest note: Q and K are just two weight matrices applied to the same input. The names are borrowed from database search. The real reason to have separate matrices: it allows asymmetric attention. "eat→bread" can be stronger than "bread→eat". ───────────────────────────────────────────────── Score every word against every other word: score("eat", "I") = q_eat · k_I / √d = 0.1 score("eat", "eat") = q_eat · k_eat / √d = 0.8 score("eat", "bread") = q_eat · k_bread / √d = 0.6 softmax → [0.10, 0.50, 0.40] new_eat = 0.10·v_I + 0.50·v_eat + 0.40·v_bread "eat" now contains info about bread (object) and I (subject) — without any RNN!
Every word does this simultaneously. "I", "eat", and "bread" all compute their attention scores in parallel, all update their representations at the same time. No sequential processing. No vanishing gradients from long chains of RNN steps. No bottleneck.
INPUT: sequence of word embeddings + positional encoding ↓ MULTI-HEAD SELF-ATTENTION Run self-attention H times in parallel. Each head asks a different question: Head 1: grammatical relationships? Head 2: semantic relationships? Head 3: positional relationships? Concatenate all outputs. One final LR to combine. ↓ ADD & NORMALIZE output = LayerNorm(input + attention_output) The "input +" is a residual connection. Gradient flows through addition without shrinking. ↓ FEEDFORWARD NETWORK Each word transformed independently. Two logistic regressions with nonlinearity. Prevents multiple attention layers from collapsing. ↓ ADD & NORMALIZE ↓ OUTPUT: richer word representations Stack this block 6, 12, 24, 96 times.
The transformer adds a few engineering necessities. Positional encoding because self-attention has no sense of order — "I eat bread" and "bread eat I" look identical to it without position signals. Residual connections because adding the input to the output of each layer creates a gradient highway that allows very deep networks to train. Layer normalization to keep numbers stable. Future masking to prevent the decoder from peeking at words it is supposed to predict.
During training, we have the full answer. Without masking, "J'aime" can see "les" and "chats". That is cheating — the model learns to copy, not predict. Solution: set future attention scores to -infinity J'aime les chats J'aime [ 0.6 -inf -inf ] les [ 0.4 0.4 -inf ] chats [ 0.3 0.3 0.4 ] After softmax: e^(-inf) = 0 → exact zero attention Future is invisible. Model must actually predict.
The transformer has three types of attention. Encoder self-attention: every input word understands every other input word. Decoder masked self-attention: every output word sees only previous output words. Cross-attention: output words look at input words — this is Bahdanau's 2014 idea, preserved inside the transformer.
"Still just logistic regression.
Extra trick: throw away the RNN. Let every word talk to every word directly. Stack it deep."
Two Moves, Six Architectures
Everything we built, everything we used
MOVE 1: Logistic Regression learns importance weight = sigmoid(W · input + b) MOVE 2: Weighted average combines information output = Σ weight_i × value_i ───────────────────────────────────────────────── Where these appear: RNN hidden state = weighted mix of past + present LSTM forget gate = LR weighting old memory LSTM input gate = LR weighting new information Attention scores = LR weighting encoder states Self-attention = LR weighting all words Multi-head = multiple LRs, multiple averages Feedforward = LR transforming individual words Every single component. Two moves. Always.
Enjoy Reading This Article?
Here are some more articles you might like to read next: